Uncategorized
Informatica Tranformation Example
Informatica Tranformation Example For Peoplesoft ERP HR data.
1. Informatica Expression (Source to Target)
2. Source Qualifier transformation
3. Expression Transformation
4. Informatica Language example use of IFF syntax.
5. performance optimisation using Oracle DECODE function inside Expression transformation
6. Hexadecimal to Decimal Conversion Logic
Bigdata,cloud , business Intelligence and Analytics
There huge amount of data being generated by BigData Chractersized by 3V (Variety,Volume,Velocity) of different variety (audio, video, text, ) huge volumes (large video feeds, audio feeds etc), and velocity ( rapid change in data , and rapid changes in new delta data being large than existing data each day…) Like facebook keep special software which keep latest data feeds posts on first layer storage server Memcached (memory caching) server bandwidth so that its not clogged and fetched quickly and posted in real time speed the old archive data stored not in front storage servers but second layer of the servers.
Bigdata 3V characteristic data likewise stored in huge (Storage Area Network) SAN of cloud storage can be controlled by IAAS (infrastucture as service) component software like Eucalyptus to create public or private cloud. PAAS (platform as service) provide platform API to control package and integrate to other components using code. while SAAS provide seamless Integration.
Now Bigdata stored in cloud can analyzed using hardtop clusters using business Intelligence and Analytic Software.
Datawahouse DW: in RDBMS database to in Hadoop Hive. Using ETL tools (like Informatica, datastage , SSIS) data can be fetched operational systems into data ware house either Hive for unstructured data or RDBMS for more structured data.
BI over cloud DW: BI can create very user friendly intuitive reports by giving user access to layer of SQL generating software layer called semantic layer which can generate SQL queries on fly depending on what user drag and drop. This like noSQL and HIVE help in analyzing unstructured data faster like data of social media long text, sentences, video feeds.At same time due to parallelism in Hadoop clusters and use of map reduce algorithm the calculations and processing can be lot quicker..which is fulling the Entry of Hadoop and cloud there.
Analytics and data mining is expension to BI. The social media data mostly being unstructured and hence cannot be analysed without categorization and hence quantification then running other algorithm for analysis..hence Analytics is the only way to get meaning from terabyte of data being populated in social media sites each day.
Even simple assumptions like test of hypothesis cannot be done with analytics on the vast unstructured data without using Analytics. Analytics differentiate itself from datawarehouse as it require much lower granularity data..or like base/raw data..which is were traditional warehouses differ. some provide a workaround by having a staging datawarehouse but still data storage here has limits and its only possible for structured data. So traditional datawarehouse solution is not fit in new 3V data analysis. here new Hadoop take position with Hive and HBase and noSQL and mining with mahout.
A day in Life of Business Intelligence Engineer
BI Requirements
Business Intelligence BI is used to analyse data to direct the resources towards area which is most productive or profitable. Slicing and dicing data available in cube(multi-dimensional data structure) along the critical areas of business defined by dimensions along which analysis has to be performed. Traditional databases are just 2 dimensional but if we need to move beyond 2 dimensional Analysis we have to used Analytical queries. Analytical Queries using functions like rank, tile etc. Are Not very Easy to conceptualize to complex requirements. These BI tools take the data and generate Analytical Queries in background seamlessly without user being aware of it.
The Need for Datawarehouse data modelling
The data from desperate Sources is accumulated into single datawarehouse or Can in subject specific data warehouse (also called Data marts). The datawarehouse consit of Facts table which is surrounded by dimension table (with ratio of about 80:20). Most data is found in Fact table. if there are more dimension to analyse beyond this 20 limit Then we can say “Too much analysis becomes paralysis”. Since there would be then lots of combinations of dimensions on which data could be analysed leading to lots of complex choices to deal with which may not be worth the effort.
So after proper business Analysis The key drivers of business are chosen along with those drivers parameters , Key performance indicators KPI , or facts are created.And also the dimensions which are critical to business are chosen to represent dimension tables.
Like for Clinical Research Company most critical driver is No. of Patients. Because if there are patients recruited by investigator (doctor) then only you can perform drug testing.
So Facts inside fact table used of analysis are measure centred around like number of patient enrolled, No. of patient suffered Adverse Effect, No. of randomized sample patient population , cost of enrolling patient etc… Now this will analysed across dimension like Geographic area (countries),Time (year 2012,2013 etc..), Study (analyse study wise),
etc…
Now Can Fact table will have numeric values facts and key of dimension tables. if its Star Schema then 2nd Normal Form of RDBMS (All non-prime attributes dependent on Prime attribute) but may have transitive dependency. Transitive dependency is removed by 3rd Normal form. A–>B (read B dependent on A), B–>C then A–>C should not be there.
When in perfect 3rd normal form Star Schema will become Snow-Flake schema with dimensions decomposed further into sub-dimensions.
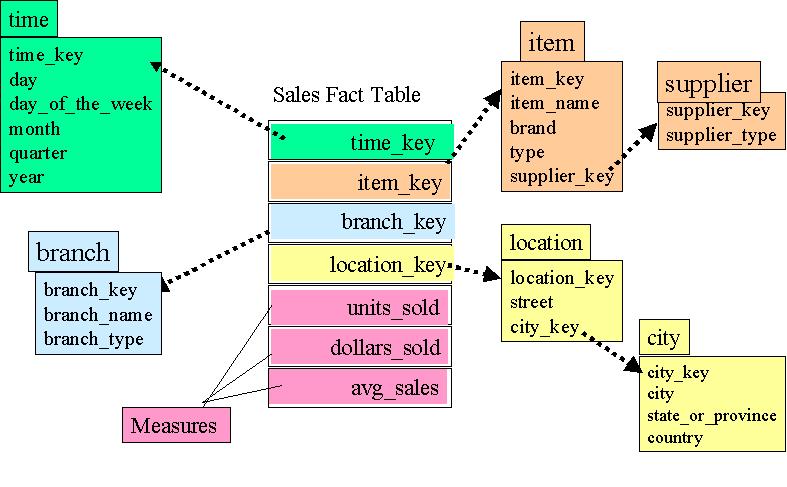 Example of Snow flake schema you can see Item dimension is further broken into supplier table.
Example of Snow flake schema you can see Item dimension is further broken into supplier table.
Cloud Computing relation to Business Intelligence and Datawarehousing
Read :
1. http://sandyclassic.wordpress.com/2013/07/02/data-warehousing-business-intelligence-and-cloud-computing/
2. http://sandyclassic.wordpress.com/2013/06/18/bigdatacloud-business-intelligence-and-analytics/
Cloud Computing and Unstructured Data Analysis Using
Apache Hadoop Hive
Read:http://sandyclassic.wordpress.com/2013/10/02/architecture-difference-between-sap-business-objects-and-ibm-cognos/
Also it compares Architecture of 2 Popular BI Tools.
Cloud Data warehouse Architecture:
http://sandyclassic.wordpress.com/2011/10/19/hadoop-its-relation-to-new-architecture-enterprise-datawarehouse/
Future of BI
No one can predict future but these are directions where it moving in BI.
http://sandyclassic.wordpress.com/2012/10/23/future-cloud-will-convergence-bisoaapp-dev-and-security/
—————————————————————————————–
A day Time Schedule of BI Engineer:
There is lifecycle flow in BI projects from requirement gather High Level Design HLD, Low Level Design LLD, using design to create report,
Choose Right Tool for report
Type of Reports:
1. Ad-hoc reports, Slice-dice (cube),
2. Event based alerts reports, Scheduling options,
3. Operational reports,
4. Complex logic report (highly customized),
5. BI App report embedded with 3rd party API,
6. Program generated report, report exposed as web service,
7. In-memory system based report like IBM Cognos TM1 or SAP HANA
8. Reports from ERP (has totally different dynamics like Bex Analyser SAP Sales and Distribution Reports). Which goes deep into domain and fetch Domain specific as well cross domain functionality. More Domain reports in SAP are fetch using SAP ABAP Report other option SAP Bex Analyser, or Web dynapro or SAP BO crystal report, or Web-Intelligence like this more than 20 favours of reports software exist with 1 Report development product like SAP BO and SAP.
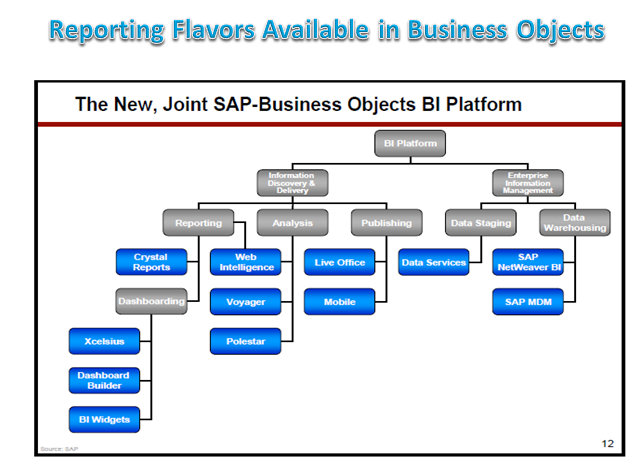 Figure: Some reporting Flavours Of SAP BO List is still not Full here. 9/14 reporting toll shown here.
Figure: Some reporting Flavours Of SAP BO List is still not Full here. 9/14 reporting toll shown here.
Which will see later this in More detail. (Can Read link above for architectural differences between two system).
9. Enterprise Search: This is Also part of BI ecosystem. Microsoft FAST or Endeca can search Enterprise repository having indexes related index to point to Right data not just document. Like SharePoint CMS searches,brings indexed documents ,set rights to view or edit, set user profile, But its not pointing to right Answers based on data.
Even Single unified metadata using Customer Data Integration CDI, can corelated equivalence between entities Across disparate ERP. Enterprise search can use this intelligence and maintain repository to throw answers to user question in search like interface.
Lets look At Each of this option in 1 product Like SAP BO/BI:
1.WebIntelligence/Desktop Intelligence
2. Crystal Reports
3. Polestar
4. Qaws
5. Xcelsious
6. Outllooksoft (planning now BPS SAP Business planning and simulation)
7. Business Explorer
8. Accelerator
Similar 14 report option Exist in BO itself. IBM Cognos (8 software) has its own options,
Microstrategy also has some (5-7) set of Reporting options.
———–
Web Dynapro
Bex Analyser
————————————————————————————
First few days should understand business otherwise cannot create effective reports.
9:00 -10am Meet customer to understands key facts which affect business.
10-12 prepare HLD High level Document containing 10,000 feet view of requirement.
version 1. it may refined later subsequent days.
12-1:30 attend scrum meeting to update status to rest of team. co-ordinate with Team Lead, Architect and project Manager for new activity assignment for new reports.
Usually person handling one domain area of business would be given that domain specific reports as during last report development resource already acquired domain knowledge.
And does not need to learn new domin..otherwise if becoming monotonus and want to move to new area. (like sales domain report for Chip manufactuers may contain demand planning etc…)
1:30-2:00 document the new reports to be worked on today.
2:00-2:30 Lunch
2:30-3:30 Look at LLD and HLD of new reports. find sources if they exist otherwise Semantic layer needs to modified.
3:30-4:00 co-ordinate with other resource reports requirement with Architect to modify semantic layer, and other reporting requirements.
4:00-5:00 Develop\code reports, conditional formatting,set scheduling option, verify data set.
5:00-5:30 Look at old defects rectify issues.(if there is separate team for defect handling then devote time on report development).
5:30-6:00 attend defect management call and present defect resolved pending issue with Testing team.
6:00-6:30 document the work done. And status of work assigned.
6:30-7:30 Look at report pending issues. Code or research work around.
7:30-8:00 report optimisation/research.
8:00=8:30 Dinner return back home.
Ofcourse has to look at bigger picture hence need to see what reports other worked on.
Then Also needed to understand ETL design , design rules/transformations used for the project. try to develop frameworks and generic report/code which can be reused.
Look at integration of these reports to ERP (SAP,peopesoft,oracle apps etc ), CMS (joomla, sharepoint), scheduling options, Cloud enablement, Ajax-fying reports web interfaces using third party library or report SDK, integration to web portals, portal creation for reports.
So these task do take time as and when they arrive.
A Day in Life of Business Intelligence (BI) Architect- part 1
BI Architect most important responsibility is maintaining semantic Layer between Datawarehouse and BI Reports.
There are basically Two Roles of Architect: BI Architect or ETL Architect in data warehousing and BI. (ETL Architect in Future posts).
Semantic Layer Creation
Once data-warehouse is built and BI reports Needs to created. Then requirement gathering phase HLD High level design and LLD Low Level design are made.
Using HLD and LLD BI semantic layer is built in SAP BO its called Universe, in IBM Cognos using framework manager create Framework old version called catalogue, In Micro strategy its called project.
Once this semantic layer is built according to report data SQL requirements.
Note: Using semantic layer saves lot of time in adjustment of changed Business Logic in future change requests.
Real issues Example: Problems in semantic Layer creation like in SAP BO: Read
http://sandyclassic.wordpress.com/2013/09/18/how-to-solve-fan-trap-and-chasm-trap/
Report Development:
Reports are created using objects created by semantic layer.Complex reporting requirement for
1. UI require decision on flavour of reporting Tool like within
There are sets of reporting tool to choose from Like in IBM Cognos choose from Query Studio, Report Studio, Event Studio, Analysis Studio, Metric Studio.
2. Tool modification using SDK features are not enough then need to modify using Java/.net of VC++ API. At html level using AJAX javascript API or integrating with 3rd party API.
3. Report level macros/API for better UI.
4. Most important is data requirement my require Coding procedure at database or consolidations of various databases. Join Excel data with RDBMS and unstructured data using report level features. Data features may be more complex than UI.
5. user/data level security,LDAP integration.
6. Complex Scheduling of reports or bursting of reports may require modification using rarely Shell script or mostly Scheduling tool.
List is endless
Read More:
details of
http://sandyclassic.wordpress.com/2014/01/26/a-day-in-life-of-bi-engineer-part-2/
Integration with Third party and Security
After This BI’s UI has to fixed to reflect customer requirement. There might be integration with other products and seamless integration of users By LDAP. And hence Objects level security, User level security of report data according to User roles.
Like a Manager see report with data The same data may not be visible to clerk when he sees same report. Due filtering of data by user roles using User Level security.
BI over Cloud
setting BI over cloud Read blog.
Cloud Computing relation to Business Intelligence and Datawarehousing
2. http://sandyclassic.wordpress.com/2013/06/18/bigdatacloud-business-intelligence-and-analytics/
Cloud Computing and Unstructured Data Analysis Using
Apache Hadoop Hive
Read: http://sandyclassic.wordpress.com/2013/10/02/architecture-difference-between-sap-business-objects-and-ibm-cognos/
Also it compares Architecture of 2 Popular BI Tools.
Cloud Data warehouse Architecture:
http://sandyclassic.wordpress.com/2011/10/19/hadoop-its-relation-to-new-architecture-enterprise-datawarehouse/
Future of BI
No one can predict future but these are directions where it moving in BI.
http://sandyclassic.wordpress.com/2012/10/23/future-cloud-will-convergence-bisoaapp-dev-and-security/
Cloud Computing, 3V ,Data warehousing and Business Intelligence
The 3V volume, variety, velocity Story:
Datawarehouses maintain data loaded from operational databases using Extract Transform Load ETL tools like informatica, datastage, Teradata ETL utilities etc…
Data is extracted from operational store (contains daily operational tactical information) in regular intervals defined by load cycles. Delta or Incremental load or full load is taken to datwarehouse containing Fact and dimension tables which are modeled on STAR (around 3NF )or SNOWFLAKE schema.
During business Analysis we come to know what is granularity at which we need to maintain data. Like (Country,product, month) may be one granularity and (State,product group,day) may be requirement for different client. It depends on key drivers what level do we need to analyse business.
There many databases which are specially made for datawarehouse requirement of low level indexing, bit map indexes, high parallel load using multiple partition clause for Select(during Analysis), insert( during load). data warehouses are optimized for those requirements.
For Analytic we require data should be at lowest level of granularity.But for normal DataWarehouses its maintained at a level of granularity as desired by business requirements as discussed above.
for Data characterized by 3V volume, velocity and variety of cloud traditional datawarehouses are not able to accommodate high volume of suppose video traffic, social networking data. RDBMS engine can load limited data to do analysis.. even if it does with large not of programs like triggers, constraints, relations etc many background processes running in background makes it slow also sometime formalizing in strict table format may be difficult that’s when data is dumped as blog in column of table. But all this slows up data read and writes. even is data is partitioned.
Since advent of Hadoop distributed data file system. data can be inserted into files and maintained using unlimited Hadoop clusters which are working parallel and execution is controlled byMap Reduce algorithm . Hence cloud file based distributed cluster databases proprietary to social networking needs like Cassandra used by facebook etc have mushroomed.Apache hadoop ecosystem have created Hive (datawarehouse)
http://sandyclassic.wordpress.com/2011/11/22/bigtable-of-google-or-dynamo-of-amazon-or-both-using-cassandra/
With Apache Hadoop Mahout Analytic Engine for real time data with high 3V data Analysis is made possible. Ecosystem has evolved to full circle Pig: data flow language,Zookeeper coordination services, Hama for massive scientific computation,
HIPI: Hadoop Image processing Interface library made large scale image processing using hadoop clusters possible.
http://hipi.cs.virginia.edu/
Realtime data is where all data of future is moving towards is getting traction with large server data logs to be analysed which made Cisco Acquired Truviso Rela time data Analytics http://www.cisco.com/web/about/ac49/ac0/ac1/ac259/truviso.html
Analytic being this of action: see Example:
http://sandyclassic.wordpress.com/2013/06/18/gini-coefficient-of-economics-and-roc-curve-machine-learning/
with innovation in hadoop ecosystem spanning every direction.. Even changes started happening in other side of cloud stack of vmware acquiring nicira. With huge peta byte of data being generated there is no way but to exponentially parallelism data processing using map reduce algorithms.
There is huge data out yet to generated with IPV6 making possible array of devices to unique IP addresses. Machine to Machine (M2M) interactions log and huge growth in video . image data from vast array of camera lying every nuke and corner of world. Data with a such epic proportions cannot be loaded and kept in RDBMS engine even for structured data and for unstructured data. Only Analytic can be used to predict behavior or agents oriented computing directing you towards your target search. Bigdatawhich technology like Apache Hadoop,Hive,HBase,Mahout, Pig, Cassandra, etc…as discussed above will make huge difference.
Some of the technology to some extent remain Vendor Locked, proprietory but Hadoop is actually completely open leading the the utilization across multiple projects. Every product have data Analysis have support to Hadoop. New libraries are added almost everyday. Map and reduce cycles are turning product architecture upside down. 3V (variety, volume,velocity) of data is increasing each day. Each day a new variety comes up, and new speed or velocity of data level broken, records of volume is broken.
The intuitive interfaces to analyse the data for business Intelligence system is changing to adjust such dynamism since we cannot look at every bit of data not even every changing data we need to our attention directed to more critical bit of data out of heap of peta-byte data generated by huge array of devices , sensors and social media. What directs us to critical bit ? As given example
http://sandyclassic.wordpress.com/2013/06/18/gini-coefficient-of-economics-and-roc-curve-machine-learning/
for Hedge funds use hedgehog language provided by :
http://www.palantir.com/library/
such processing can be achieved using Hadoop or map-reduce algorithm. There are plethora of tools and technology which are make development process fast. New companies are coming from ecosystem which are developing tools and IDE to make transition to this new development easy and fast.
When market gets commodatizatied as it hits plateu of marginal gains of first mover advantage the ability to execute becomes critical. What Big data changes is cross Analysis kind of first mover validation before actually moving. Here speed of execution will become more critical. As production function Innovation givesreturns in multiple. so the differentiate or die or Analyse and Execute feedback as quick and move faster is market…
This will make cloud computing development tools faster to develop with crowd sourcing, big data and social Analytic feedback.
Hadoop its relation to new Architecture, Enterprise datawarehouse.
Hadoop is more used for Massive Parallel processing MPP architecture.
new MPP platform which can scaleout to petabyte database hadoop which is open source community(around apache, vendor agnostic framework in MPP), can help in faster precessing of heavy loads. Mapreduce can be used for further customisation.
hadoop can help roles CTO : log analysis of huge data of suppose application logging millions of transaction data .
CMO: targetted offering from social data, target advertisements and customer offerings.
CFO : on using predictive analytics to find toxicity of Loan or mortage from social data of prespects.
datawarehousing and BI we report to CTO only.But it getting pervasive..so user load in BI System increase leading to efficient processing through system like hadoop of social data.
hadoop can help in near realtime analysis of customer like customer click stream real-time analysis,(realtime changing customer interest can be checked over portal ).
Can bring paradigm shift in Next generation enterprise EDW,SOA(hadoop). Mapreduce in data virtualitzation.In cloud we have (platform,Infrastructure,software).
mahout : Framework for machine learning for analyzing huge data and predictive analytic on it. Open source framework support for Mapreduce.Real time analytic helps in figuring trend very early from customer perspective hence adoption level should be high in customer Relationship management modules so it growth of Salesforce.com depicts.
HDFS: is suited for batch processing.
HBase: for but near realtime
casendra : optimized real tim e distributed environment.
Hr Analytics: There are high degree of silos: cycle through lots survey data :–> prepare report –> generalized problem –> find solutions for generalized data . Data from perspective of application, application as perspective of data.
BI help us in getting single version of truth about structure data but unstructured data is where Hadoop helps. Hadoop can process: (structureed,un-structured, timeline etc..across enteripse) data.from service oriented Architeture we need to move from SOA towards SOBA Service oriented business Architecture.SOBAs are applications composed of services in a declarative manner .The SOA Programming Model specifications include the Service Component Architecture (SCA) to simplify the development of creating business services and Service Data Objects (SDO) for accessing data residing in multiple locations and formats.Moving towards data driven application architectures.Rather than application arranged around data have to otherwise application arranged around data.
Architect view point: 1. people and process as overlay of technology. Expose data trough service oriented data access. Hadoop helps in processing power in MDM, quality, integrating data outside enterprise.
utility Industry:Is the first industry to adopt Cloud services with smart metering. Which can give smart input to user about load in network rather then calling services provider user is self aware..Its like Oracle brought this concept of Self service applications.
I am going to refine matter further put some more example and ilustrations if time permits..
A day in Life of datawarehousing Engineer Part-2
Read Previous part
http://sandyclassic.wordpress.com/2014/02/19/a-day-in-life-of-datawarehousing-engineer/
Normal Schedule for development role :
9:00-9:30 Check all mail communications of late night loads Etc.
9:30-10:30 Attend Scrum meeting to discuss update status of completed task mappings and mapping for New user stories requirements, understand big picture of work completed by other staff status.
10:30 am -1:30 pm Look at LLD, HLD to create source to target transformations after understanding business logic and coding that in transformations available with tool.
1:30-2:00 Lunch break
2:00-3:00 Unit test data set to validate as required between source and target.
3:00-3:30 Documentation requirements of completed work.
3:30-4:30 Attend defect Call To look into new defects in code and convey back if defects not acceptable as out of scope or not according to specifications.
4:30-5:00 Status update daily work to Team Lead.
5:00-5:30 sit with Team lead, architect code walk through and update with team.
5:30-6:30 Take up any defects raised in Defect meting and Code walk through.
Architecture sap hana vs oracle exadata competitive analysis part -2
READ part 1:
http://sandyclassic.wordpress.com/2011/11/04/architecture-and-sap-hana-vs-oracle-exadata-competitive-analysis/
This debate of SAP Vs Oracle or last 2 yrs buzz SAP HANA vs Oracle Exalytics
Every year in Enterprise Software space Competition of SAP Vs Oracle Hots up with new announcements and New technology comparisons of SAP new Tech Vs Oracle New Tech.
The Enterprise Software stack built up by No.1 and No.2 world’s top most valued companies in Enterprise Technology Space.
So SAP Vs Oracle comparison will never go out of picture only every year it will up the ante.
In Memory Technology: SAP Vs Oracle (New tech now 2 yrs old).
Now a day In-Memory Technology is the Hottest area especially in Business Intelligence (BI). But its not limited to BI it goes into ERP, Application development of any Kind.
The processing infrastructure in form of in Memory Systems is much faster than any other form. As Cost of RAM is coming down and capacity of server is expanding So most data to be processed can be pulled inside memory at once instead of using Locality of reference to pull and process from secondary memory.
Also Server can hold lot more data to processed in memory at once.
SAP HANA Vs Oracle Exadata
So SAP Came with SAP HANA and Oracle has its own in memory systems. At same time Oracle released high performance machine Exadata which brook many performance records. So There was running comparisons of SAP Vs Oracle in Enterprise Technology space.
innovation at SAP : ABAP, BSP and BAPI
SAP customized by using Advanced Business Application Programming (ABAP) Language.
Using which reports are customized, forms are modified, business processes are written to reflect business Logic. ILE, BAPI, IDOC can be used to interface with external software or integration or developing Adaptor. Custom Exits and User Exits are written to customize forms and reports.
For SAP datawarehouse technology SAP BIW or SAP BI datawarehouse is created using
Extraction Legacy System Migration Workbench (LSMW) or Cost and profitability Analysis (COPA) Extrations then transformation can be applied using ABAP user exits.
Problem with ABAP is compared to mordern langauges it has not evolved much over time.
Most of ABAP constructs are similar to COBOL constructs. There is Object oriented ABAP also like JSP or ASP it came up with BSP (Business Server Pages) to Expose ABAP code directly to Web like JSP does for Java or ASP does for Microsoft Technology.
SAP Netweaver Vs SAP ABAP BSP
SAP began adopting Java in 2003 and came up with Netweaver product which was J2EE server for ABAP code. Now you can code using either java or ABAP in netweaver. For Application requiring functionality to exposed to Web Java was natural choice.
But Oracle having acquired Java in year 2010 Since then there was continuous Effort on part of SAP to move away from its dependence of Java. So BSP came into picture as first step.
Benefits of In-memory in SAP HANA
next was paradigm shift using Columar database instead of Row oriented databases which consumed less storage (on account of reduction in repetitions of similar column values as well compression of data).
Also it integrates:
BI and datawarehousing system or OLAP with
Operational systems or OLTP Systems as one.
Even Analytic requiring lowest level of granularity can be queried on same server.
Effect of which was Whole data can be pulled and kept in In-memory system offering faster response time to multiple user connected at same time rather than
Regular database Query processing logic
parsing request , making parse tree,
comparing with already fetched query parse tree in cache
if not available
then
fetching data from secondary memory
when depending on the request into
Improvement in data processing in SAP HANA and column oriented database
Now since whole data can be kept in-memory So Every query can directly fetch data quicker.
Future Technology Like SAP HANA
Enhancement over this Technology are Probabilistic databases and Graph databases.
Graph databases are available commercially since long time.
Index free storage. Every element has direct pointer to adjacent element, hence no lookup needed.
Here is list:
http://en.wikipedia.org/wiki/Graph_database
And
Probabilistic databases : Are active area of research as discussed above as well.
http://en.wikipedia.org/wiki/Probabilistic_database
IBM information Server Architecture: InfoSphere DataStage Server Architecture
IBM information Server Architecture: InfoSphere DataStage Server Architecture
